
Is Your NGS Workflow Holding You Back?
Part 2: How the ExpressPlex™ Workflow Engineers Scalable Simplicity.
In Part 1 of seqWell’s Workflow Matters series, we made the case that library prep is a workflow decision — one that directly determines throughput, data reliability, and ultimately what science is feasible. If you haven’t read it yet, start there.
The question we left open: what does a workflow engineered for scalable simplicity actually look like?
The ExpressPlex™ workflow was built to answer that. Powering seqWell solutions including ExpressPlex 2.0, ExpressPlex Plus, and AgriPrep, it integrates chemistry and operational engineering into a unified scalable system — designed to maintain efficiency and consistency whether you’re processing 96 samples or tens of thousands.
Scalable Simplicity: The Design Goal
Most workflows are designed to work. The ExpressPlex workflow was designed to scale — a distinction that matters enormously once throughput starts climbing.
Rather than optimizing individual steps in isolation, the ExpressPlex workflow fully integrates chemistry, automation compatibility, and multiplexing strategy. The result is what seqWell calls scalable simplicity: a workflow that doesn’t just minimize steps at low volume but maintains that efficiency as sample counts grow.
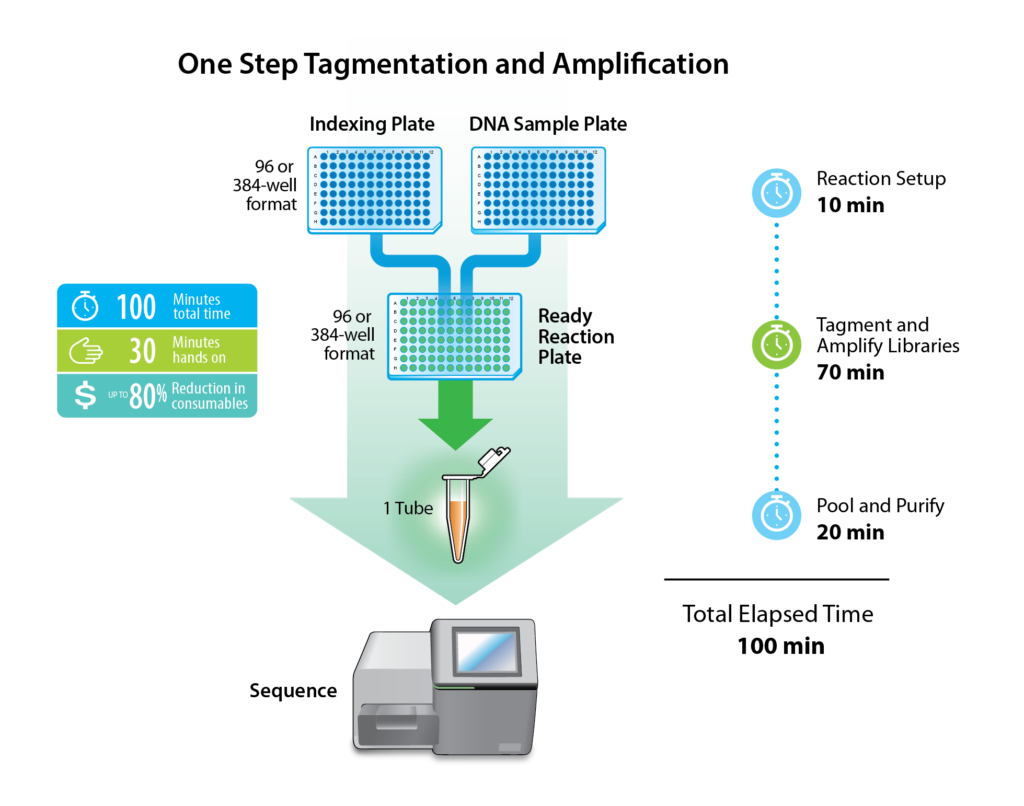 ExpressPlex™ workflow: from samples to sequencer-ready pools in ~100 minutes, with up to 90% reduction in consumables.
ExpressPlex™ workflow: from samples to sequencer-ready pools in ~100 minutes, with up to 90% reduction in consumables.
The workflow combines seqWell’s engineered TnX™ next-generation transposase with protocol innovations that compress library prep into approximately 100 minutes — without sacrificing coverage uniformity.
ExpressPlex workflow key features:
-
- One-step tagmentation and amplification
- Auto-normalization with early pooling
- Pre-plated index and ready-reaction formats (96- and 384-well)
- Automation-ready design
- >6,000 unique indexes for large-scale multiplexing
Here is how each of those design choices translates into operational and scientific impact.
One-Step Consolidation: Fragmentation, Tagging, & Amplification
Traditional Illumina-compatible workflows separate fragmentation, end repair, adapter ligation, and amplification into sequential reactions — each requiring its own reagent additions, incubation steps, and/or bead cleanup. That isn’t just slow; it’s a compounding source of variability.
The ExpressPlex workflow replaces that multi-step sequence with a single reaction. Using the engineered TnX transposase, DNA is simultaneously fragmented and tagged with sequencing adapters, then immediately amplified — no intermediate cleanup, no additional reagent transfers between steps.
What this changes in practice:
-
- Eliminates multiple enzymatic and bead-cleanup steps
- Reduces pipetting touches and the variability each transfer introduces
- Shortens total protocol time and hands-on time from input DNA through amplified library
At low sample numbers, this is convenient. At high sample numbers, it is transformative — fewer steps mean fewer opportunities for error or sample mix-up, and reproducibility gains compound across plates, operators, and sites.
Auto-Normalization Removes a Chronically Underestimated Bottleneck
Ask any high-throughput lab where their workflow loses time, and normalization will be near the top of the list. Quantifying every sample, calculating dilutions, and executing them accurately is labor-intensive at 96 samples and operationally punishing at scale. It also consumes a disproportionate number of tips, plates, and reagent volumes per sample processed.
The ExpressPlex workflow eliminates this step through built-in auto-normalization. Input samples and post-amplification libraries no longer require individual quantification and dilution before pooling — the workflow handles it.
Operational impact:
-
- Significant reduction in hands-on time per batch
- Fewer consumables — tips, plates, and reagents — per sample prepared
- Reduced operator variability between samples and between runs
- Simpler handling of heterogeneous sample inputs with fewer touchpoints
For labs processing hundreds or thousands of samples, eliminating normalization isn’t a minor convenience — it’s the removal of a major rate-limiting step, with direct effects on throughput, cost per library, and how many projects a given team can realistically run.
High-Level Multiplexing and Early Pooling
Throughput isn’t only about how fast libraries are made — it’s about how efficiently samples move onto the sequencer. Large-scale multiplexing is what connects library prep speed to sequencing economics.
The ExpressPlex workflow supports over 6,000 unique combinatorial indexes, enabling highly multiplexed pooling strategies that maximize samples per sequencing run. Critically, samples are barcoded and pooled early in the workflow — condensing plate-based processing into single tubes and dramatically reducing downstream handling.
Why this matters:
-
- More samples per run: better utilization of sequencing capacity and lower cost per data point.
- Earlier pooling: fewer plates to handle downstream, fewer error-prone transfers, fewer consumables.
- Higher multiplexing depth: the economics of sequencing improve in direct proportion to how efficiently you fill a run.
The math is straightforward: the more samples you can index and pool efficiently, the lower the sequencing cost per sample — and the more each run contributes directly to science rather than infrastructure.
Engineered TnX: Workflow Efficiency Without Compromising Data Quality
Workflow efficiency is only valuable if the data coming out is worth analyzing. That’s where the chemistry at the core of the ExpressPlex workflow matters.
The engineered TnX transposase was specifically designed to reduce insertion site bias and improve coverage uniformity across diverse sequence contexts.
In practical terms:
-
- More uniform fragmentation and adapter insertion across the genome
- Better representation across sequence contexts
- More consistent library quality across samples, plates, and runs
For high-throughput workflows, coverage uniformity isn’t just a quality metric — it’s an efficiency metric. Poor uniformity forces over-sequencing to ensure adequate depth across all targets. Improved uniformity means fewer failed libraries, less repeat sequencing, and higher confidence in every run — directly reducing both cost and turnaround time.
Automation-Ready by Design
Workflows that look efficient on paper can become increasingly fragile as throughput scales — particularly if automation compatibility was an afterthought. The ExpressPlex workflow was designed from the ground up for high-throughput automated environments.
Reagents are provided in pre-plated 96- and 384-well formats with indexing reagents already arrayed. There are no required dilutions, no pre-run aliquoting, and no reagent transfers before reaction setup. Reaction setup can be completed in under 10 minutes.
Operational benefits:
-
- Direct integration with standard liquid handling platforms
- Minimal pre-run setup variability
- Consistent reagent distribution across all samples in the plate
- Lower cross-contamination risk
- Exponential throughput gains
For labs running automation, this means simpler scripting and higher run-to-run consistency. For labs that aren’t yet automated, the same plate-based format keeps manual execution straightforward and reproducible — making the transition to automation, when it comes, nearly seamless.
From Design to Results: Time and Cost in Practice
The cumulative effect of these design choices is substantial. Across seqWell kits powered by the ExpressPlex workflow, library preparation is typically completed in:
-
- ~100–120 minutes total workflow time
- Under 30 minutes of hands-on time
That’s not just faster — it’s uniquely fast. Many workflows accumulate overhead rapidly as sample counts climb. The ExpressPlex workflow was engineered to avoid that pattern: efficiency holds at scale, so labs can increase output without proportional increases in labor, consumables, or operational complexity.
Across a high-volume operation, this translates to:
-
- More samples processed per FTE per day
- Meaningful reductions in consumable cost and plastic waste
- Lower rework and repeat sequencing rates
- Overall lower sequencing cost per sample
Most importantly, these gains scale with sample volume. The ExpressPlex workflow is designed so that the efficiency advantage grows — not erodes — as throughput increases.
See the Hidden Savings of the ExpressPlex Workflow for Yourself!
ExpressPlex Hidden Savings Infographic
From Design to Results: Time and Cost in Practice
As we discussed in Part 1, throughput constraints don’t stay operational for long — they become scientific constraints. When workflows limit how many samples you can process, they limit how many questions you can ask, how quickly you can iterate, and what studies are actually feasible.
The ExpressPlex workflow was built on a different premise: that simplifying a workflow at scale is what genuinely unlocks scientific capacity — not just operational convenience.
By integrating one-step tagmentation chemistry, auto-normalization, high-level multiplexing, TnX-driven coverage uniformity, and automation-ready formats into a single cohesive system, the ExpressPlex workflow transforms library prep from a rate-limiting step into a scalable engine for discovery.
The workflows that enable the most science aren’t necessarily the most sophisticated. They’re the ones that stay simple, consistent, and efficient — at any throughput.
Ready to Move Past Workflow as the Limiting Reagent?
Turn library prep into an advantage rather than a bottleneck.